

Vous pouvez regarder une vidéo pour en savoir plus sur l'utilisation des jours spéciaux pour améliorer la précision des prévisions.
Lorsque vous examinez l’étape des données de prévision, vous voyez à la fois le volume prévu et l’AHT pour toutes les compétences sélectionnées. Les données peuvent sembler inexactes, alors que vous vous attendez à voir des valeurs normales :
-
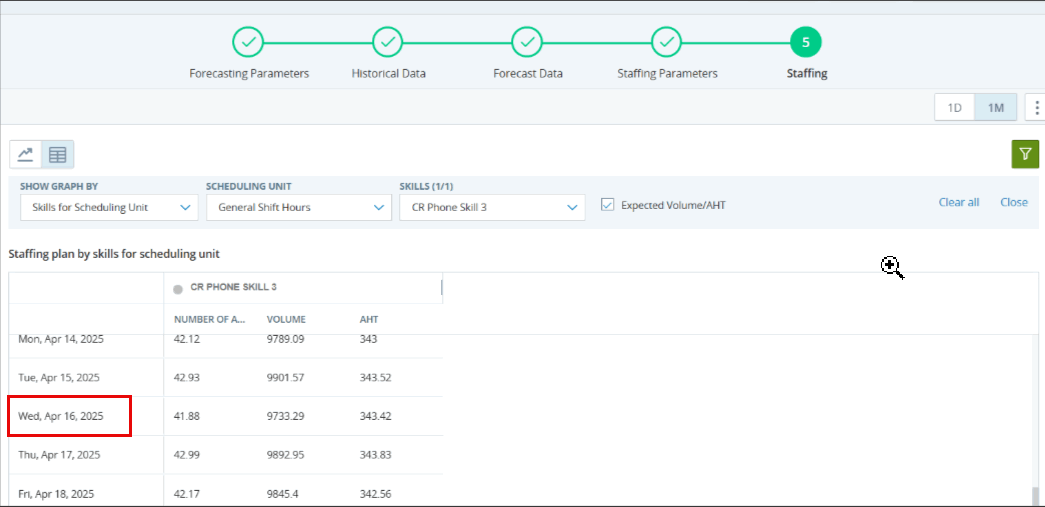
Vous voyez dans certaines zones où l’AHT ou le volume est anormalement bas ou à 0,00.
-
Vous voyez des pics de volume le mardi et le mercredi, mais les données historiques montrent des pics le lundi et des tendances à la baisse jusqu’à vendredi.
Dans ces cas, envisagez d’apporter des modifications aux données historiques.
À l’étape Données historiques, recherchez les jours qui ne suivent pas tout à fait la norme. Par exemple, les volumes peuvent être trop élevés pour un certain jour en raison d’une promotion de produit. Ce n’est pas une journée standard. Pour cette raison, les données de prévision afficheront un volume ou AHT inexact pour certaines compétences.
Pour améliorer la précision des volumes prévus et AHT, définissez ces jours comme Journées spéciales. Dans les paramètres du jour spécial, choisissez d’exclure ce jour des prévisions futures. Ces jours ne seront pas pris en compte dans l’étape de prévision des données.
Lorsque le volume d'interaction prévu pour une journée entière est de 0, vous ne pourrez pas modifier le volume.
Vous pouvez vérifier que le volume de la journée entière est égal à 0 en consultant les données par jour (1D). Dans la vue journalière, les données s’affichent pour chaque intervalle de la journée.
Si le volume de tous les intervalles est égal à 0, vous ne pouvez pas modifier les données.
Pour pouvoir modifier le volume, changez au moins un intervalle.
Par exemple, le volume d’interactions prévu est de 0 le 25 janvier. Vous êtes actuellement en train de regarder la vue mensuelle (1M). Dans ce cas, vous ne pourrez pas effectuer de modification simple ou de modification en vrac.
Pour modifier le volume du 25 :
-
Passez à la vue journalière (1D).
-
Modifiez au moins un intervalle. Disons 25 janvier 8h00. Au lieu de 0, écrivez 1 ou la valeur souhaitée pour cet intervalle.
-
Pour apporter des modifications à l’ensemble de la journée, revenez à la vue du mois (1M) et modifiez-la.
Lorsque vous créez une tâche de prévision, le système calcule les données prévisionnelles en deux étapes. Tout d’abord, les données sont générées dans Données prévisionnelles (étape 3 de la prévision), sur la base des compétences requises. Deuxièmement, le système peut améliorer les données prévisionnelles en répartissant la charge de travail entre plusieurs unités de planification. Après avoir défini les paramètres de dotation en personnel (étape 4), les données sont régénérées. Cette fois, le calcul prend également en compte les unités de planification qui peuvent gérer les interactions. Cela permet de garantir que les données prévisionnelles sont aussi précises que possible. Les données prévisionnelles sont mises à jour dans Dotation en personnel (étape 5).
Lorsque vous créez une planification basée sur une tâche de prévision, les données prévisionnelles sont basées sur les données de l’étape 5. Les données de la prévision finale sont également affichées dans les colonnes Prévisions dans Gestionnaire intrajournalier.
Au cours du processus de prévision (étape 3), il s’agit de générer une prévision brute, en se concentrant uniquement sur le volume et le temps de traitement moyen (AHT) par compétence, sans tenir compte des agents. De l'étape 3 à l'étape 5, un processus de simulation se produit, distribuant les besoins des agents à chaque unité de planification qui gère les compétences prévues. Ces exigences sont ensuite traduites en volume par compétence et par unité de planification.
À l’étape 5, comme indiqué dans la capture d’écran, on peut observer le volume et l’AHT pour l’intervalle de 8h00 à 8h15, indiquant le nombre attendu de contacts à traiter par unité de planification par compétence à la suite de la simulation.
Disons que vous avez activé ACD en avril 2021. C’est à ce moment-là que les données historiques commencent à être collectées. Ensuite, vous avez activé WFM le 20 novembre 2022. Comme vous collectez des données historiques depuis plus d’un an, vous devriez être en mesure de les utiliser automatiquement lors de l’élaboration des prévisions.
Cependant, la tâche de prévision indique qu’il n’y a pas de données historiques (à l’étape 2). Pour résoudre ce problème, vous devez contacter le soutien. Ils importeront les données historiques que vous avez collectées dans WFM.
Le système fonctionne comme prévu. La fonction de sélection automatique choisit automatiquement le meilleur modèle de prévision en fonction des données passées. Dans ce cas, le système a choisi le modèle qui semblait le plus précis pour les données qui lui étaient fournies. Bien que cela ait produit un pic le jeudi, cela fait partie de la fonction prévue du système : il a sélectionné ce qui semblait être la meilleure option en fonction des résultats passés.
La différence dans les résultats provient de la façon dont les deux modèles traitent les données :
-
Le modèle de sélection automatique a choisi une méthode de prévision qui fonctionnait le mieux pour les données passées, mais il a détecté un modèle hebdomadaire (comme le pic du jeudi) et l'a reporté dans le futur.
-
Le modèle de lissage exponentiel (ES) lisse les données, ce qui les rend moins sensibles aux pics du jeudi et produit une prévision plus stable.
Les deux modèles donnent des résultats différents parce qu'ils sont conçus pour gérer les données de différentes manières, et chaque modèle a ses forces en fonction du comportement des données.
Le modèle de sélection automatique fait exactement ce pour quoi il a été conçu : il choisit le modèle qui, selon lui, donnera les prévisions les plus précises en fonction des données historiques. Cependant, dans de rares cas comme celui-ci, le modèle peut détecter des patrons inhabituels qui ne se vérifient pas à l'avenir, comme le pic de jeudi. Le client peut utiliser la fonction de sélection automatique, mais dans certaines situations spécifiques, il peut avoir besoin de choisir manuellement un modèle différent (comme le lissage exponentiel) pour obtenir une prévision plus précise.
Étant donné que le client est titulaire d'une licence avancée, il a la possibilité de sélectionner manuellement le modèle de prévision chaque fois qu'il estime que le modèle sélectionné automatiquement ne donne pas les meilleurs résultats. Cette flexibilité leur permet de choisir le modèle le plus adapté à leurs besoins spécifiques.
Dans l'écran de dotation en personnel pour le poste ci-dessous, considérons un intervalle le 15 janvier pour la compétence « Centre de contact », comme le montre l'image ci-dessous :
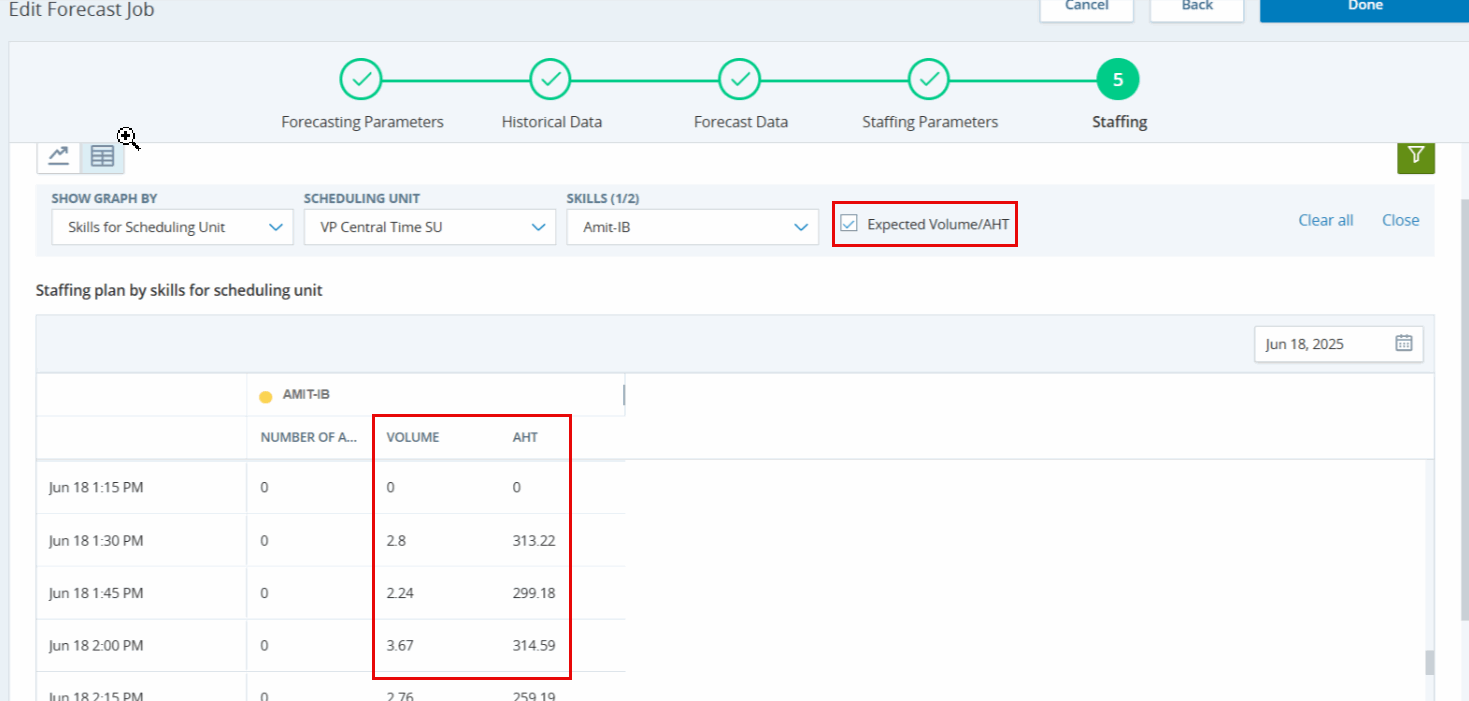
Dans l'exemple ci-dessus, on peut voir que le volume est de 4,71 avec un AHT de 100,43 pour la compétence Centre de contact. Cela signifie que dans un intervalle de 900 secondes (15 minutes), tous les appels seront traités par un seul agent avec un AHT de 100,43. Si on utilise les chiffres exacts dans nos calculs, le besoin en personnel de 0,53 est correct, car il y a 67 agents dans l'unité de planification.
Le changement du niveau de service n’a pas d’impact sur le personnel parce que nous avons suffisamment d’agents pour gérer les appels. Lorsque nous examinons la configuration du centre de contact dans l'unité de planification lors de la génération du personnel, nous constatons qu'il y a un total de 67 agents disponibles pour gérer les appels pour la compétence sélectionnée. Par conséquent, lorsque les besoins en personnel sont générés, s'il y a suffisamment d'agents disponibles pour gérer les interactions prévues dans chaque intervalle, le SLA ASA n'est pas pris en compte.
Toutefois, si le nombre d'agents disponibles pour gérer les appels prévus au cours d'un intervalle donné est insuffisant, la mesure SLA ASA est utilisée pour déterminer le nombre d'agents nécessaires pour atteindre les objectifs de niveau de service. Ce principe s'applique à tous les intervalles, compétences et unités de planification pour ce rôle. Compte tenu du faible volume et de l'AHT, ainsi que du nombre adéquat d'agents disponibles, les effectifs restent inchangés, puisqu'il y a suffisamment d'agents pour respecter systématiquement le SLA à 100 %, l'ASA est effectivement calculé à zéro.
Selon la demande de données historiques, nous vérifions si la compétence ACD est entrante ou sortante et si la direction de la compétence WEM est entrante ou sortante. Si elles ne correspondent pas, un message sur la page historique indique une incompatibilité de direction.
Message d’erreur :
-
Les compétences WEM ne correspondent pas à celles d’ACD. Alignez ces compétences WEM avec ACD : Soutien à la clientèle OB.
Causes possibles :
-
Cas 1 : La compétence WEM est entrante, mais la compétence ACD qui lui est associée est sortante.
-
Cas 2 : Les compétences WEM et ACD sont toutes deux sortantes, mais les données historiques téléchargées sont marquées comme entrantes.
-
Cas 3 : Les compétences WEM et ACD sont toutes deux entrantes, mais les données historiques téléchargées sont marquées comme sortantes car l’indicateur sortant est défini sur True pendant le téléchargement.
-
Cas 4 : La compétence ACD a été supprimée et recréée. Dans ce cas, la correspondance initiale entre la compétence WEM et la compétence ACD est perdue.
Solution de contournement :
-
Assurez-vous que les données historiques sont téléchargées conformément à la configuration des compétences ACD. Si la compétence ACD est définie comme sortante, définissez isOutboundFlag sur True pendant le téléchargement. Sinon, si la compétence ACD est définie comme entrante, définissez le isOutboundFlag sur False.
-
Si une compétence ACD a été supprimée puis recréée, réaffectez la compétence WEM à la compétence ACD nouvellement créée.
-
Dans les cas où une compétence ACD est mappée comme entrante, mais que la compétence WEM associée a le Assigner au canal défini sur composeur, la compétence WEM doit être supprimée. Créez une nouvelle compétence WEM de type entrant et associez-la à la compétence ACD entrante appropriée.
-
Rechargez les données historiques à partir de WFM > Prévision > Données historiques ACD et assurez-vous qu’au moins 13 semaines de données historiques sont disponibles pour des prévisions précises.
Dans CXone Mpower WFM, Target ASA (Average Speed of Answer) est un paramètre optionnel utilisé dans les calculs de dotation en personnel.
-
Vous pouvez définir un ASA cible dans le cadre de vos paramètres de dotation en personnel, mais ce n’est pas obligatoire.
-
Si vous ne définissez pas d’ASA cible, le processus de dotation en personnel s’exécutera quand même en utilisant d’autres entrées, comme le Niveau de service cible, pour générer des recommandations en matière de dotation en personnel.
Lors de la génération des effectifs, le système exécute une simulation qui modélise la manière dont les contacts arrivent, sont mis en file d’attente et sont traités dans un système ACD réel. À partir de cette simulation, le système détermine :
-
Le nombre d’agents requis pour atteindre les objectifs définis (Niveau de service et/ou ASA).
-
Le temps d’attente réel moyen que les clients subiraient avec le personnel calculé.
Ce temps d’attente réel devient l’ASA prévisionnel affiché en intraday.
-
Si une ASA cible est définie, l’ASA prévisionnelle reflète le résultat de la simulation en fonction de cet objectif.
-
Si aucune ASA cible n’est définie, l’ASA prévisionnelle est quand même calculée automatiquement dans le cadre de la simulation basée sur le niveau de service.
Que l’ASA cible soit configurée ou non, Intraday affiche toujours une ASA prévisionnelle basée sur la simulation des effectifs.
Lorsque plusieurs cibles de service telles que Niveau de service, ASA cible et Occupation maximale sont définies pour la même Compétence WEM, CXone Mpower WFM évalue toutes les cibles simultanément pendant la simulation de dotation en personnel.
-
Le système calcule le nombre d’agents nécessaires pour atteindre chaque objectif individuel.
-
Elle choisit ensuite parmi elles celle qui requiert le plus de personnel.
Par exemple :
-
L’objectif de Niveau de service nécessite 20 agents
-
L’objectif ASA nécessite 22 agents
-
L’Occupation maximale nécessite 18 agents
-
Besoin final en personnel = 22 agents (le maximum des trois)
-
Cette approche garantit que les recommandations en matière de personnel répondent à tous les objectifs de service définis, et non à un seul.
Lorsque plusieurs objectifs de service sont définis pour la même Compétence WEM, le système affecte toujours les effectifs à l’exigence la plus restrictive (la plus importante) afin de s’assurer que tous les objectifs soient atteints.
Il n’est généralement pas recommandé de définir plusieurs cibles de service pour une même Compétence WEM. Chaque objectif influe différemment sur les effectifs et peut engendrer des contraintes contradictoires. Par exemple,
-
Niveau de service et objectif ASA : l’objectif est de réduire les temps d’attente des clients.
-
L’Occupation maximale limite l’utilisation des agents, ce qui peut entrer en conflit avec les objectifs de SL et d’ASA.
Malgré cela, CXone Mpower WFM offre la flexibilité nécessaire pour prendre en charge de tels scénarios au besoin. Le calculateur de Dotation en personnel évalue plusieurs cibles sélectionnées, qu’elles soient définies dans le profil de dotation en personnel ou directement dans le poste prévisionnel, et génère des recommandations de dotation en personnel qui les satisfont simultanément.
Il incombe à l’utilisateur de s’assurer que les cibles sélectionnées sont alignées et ne sont pas conflictuelles. L’activation de plusieurs cibles accroît la rigidité de la solution de dotation en personnel, ce qui peut entraîner un sureffectif ou des horaires irréalisables.
L’algorithme de prévision utilise différentes méthodes pour calculer le temps de transfert moyen (AHT) en fonction de la quantité de données historiques disponibles :
Si les données historiques disponibles couvrent moins de 2 ans :
-
L’algorithme utilise une moyenne pondérée mobile pour estimer l’AHT.
-
Ce calcul est effectué au niveau de l’intervalle, en appliquant des pondérations aux points de données récents au sein de chaque intervalle de temps (par exemple, des blocs de 15 ou 30 minutes).
Si plus de 2 ans de données historiques sont disponibles :
-
L’algorithme évalue plusieurs modèles candidats et sélectionne celui avec l’erreur absolue moyenne (MAE) la plus faible .
-
Cette sélection de modèle est également appliquée au niveau de l’intervalle, permettant à chaque intervalle d’utiliser le modèle le mieux adapté en fonction de son comportement historique en matière de temps de séjour moyen (AHT).
Résumé:
-
< 2 ans de données : Moyenne pondérée mobile → appliquée au niveau de l’intervalle.
-
≥ 2 ans de données : Modèle le mieux adapté sélectionné à l’aide de MAE → appliqué au niveau de l’intervalle.